Parsing pages with XPath. Today I will tell you how you can make parsers of remote HTML pages (in PHP). In this article I will show you how to perform xpath queries to Web pages. XPath – a query language to elements of xml or xhtml document. To obtain the necessary data, we just need to create the necessary query. For the work, we also need: browser Mozilla Firefox, firebug and firepath plugins. For our experiment, I suggest this webpage Google Sci/Tech News. Of course you can choose any other web page too.
Ok, lets start, firstly make sure that both plugins installed in your browser. Then lets open our page with news (Google Sci/Tech News page). After – clicking the right mouse button at any description text, as example inside ‘A Samsung Electronics Co. Galaxy S smartphone, top…’ text, and in popup menu selecting ‘Inspect in Firepath’
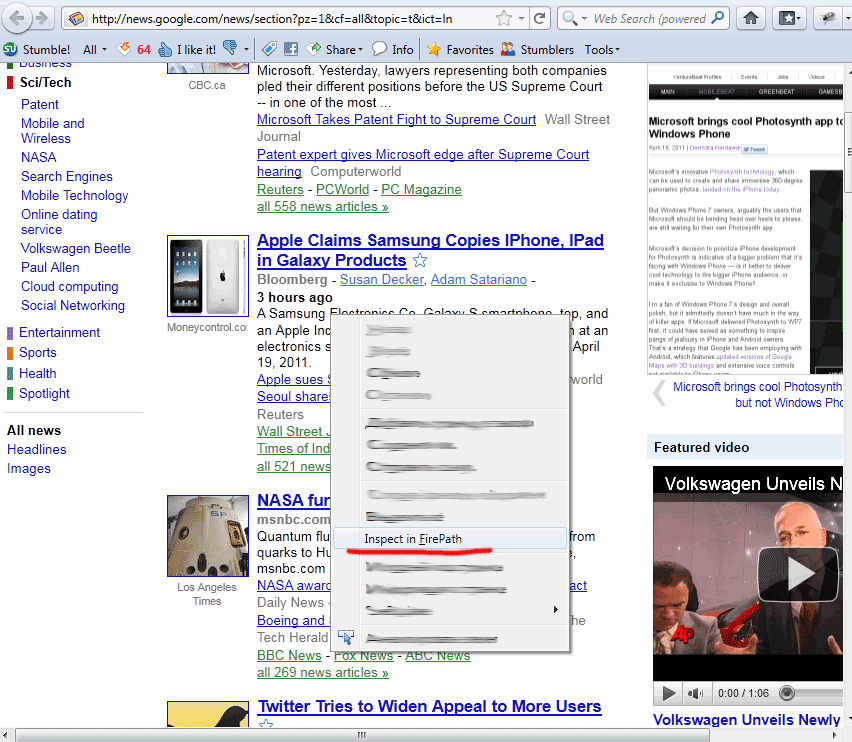
as result – we will see next:
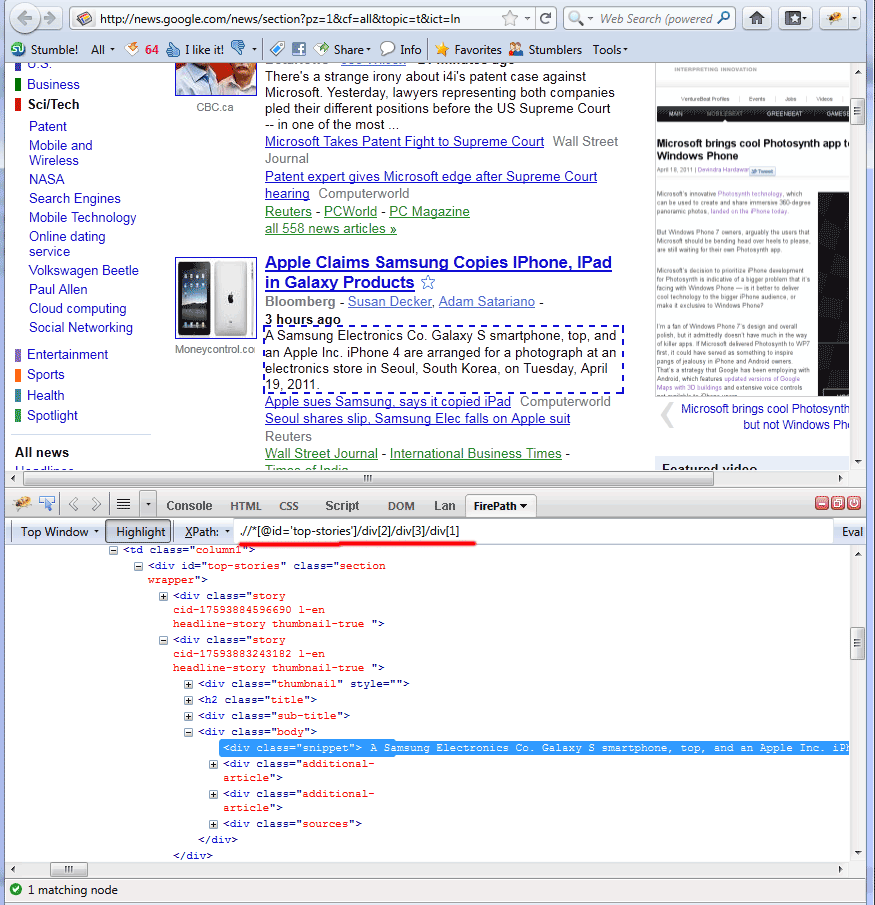
Make attention to XPath: .//*[@id=’top-stories’]/div[2]/div[3]/div[1]
The result will be highlighted by the dashed line. After cleanup all unnecessary indexes and small corrections – we will get next query: .//*[@id=’top-stories’]/div/div[@class=’body’]/div[1]
Try to execute it, as result we will see next:
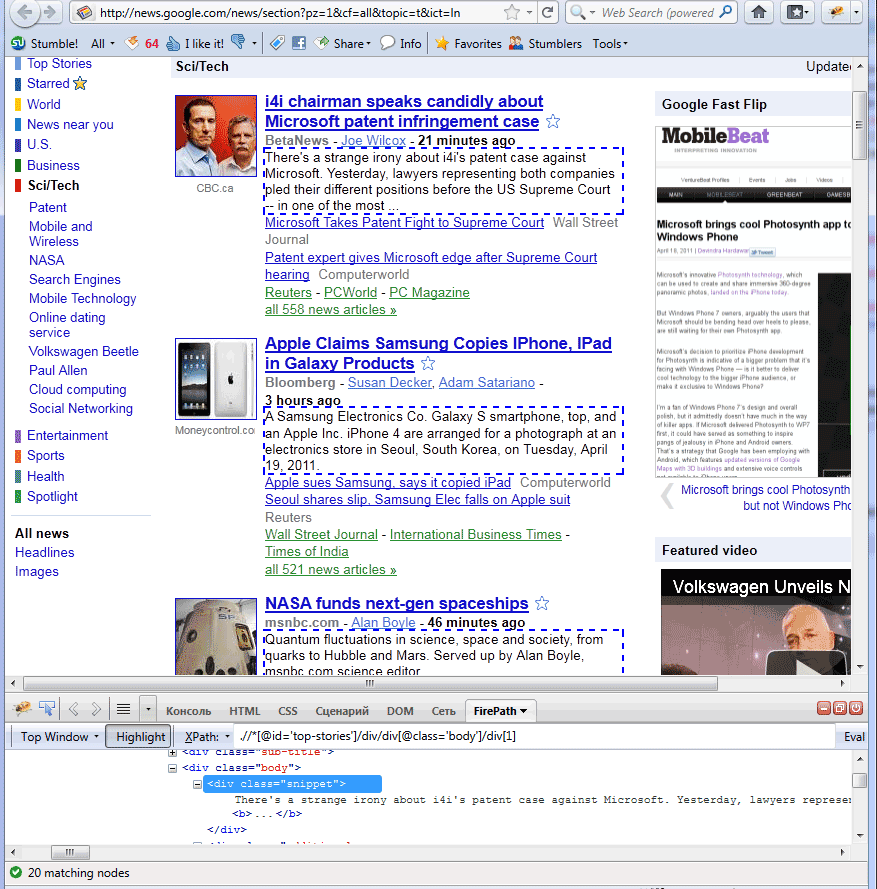
So in result – we selected all descriptions (Firepath plugin will highlight elements with dashed line all query results plus will select these node elements in DOM too – look to Firepath tab of Firebug).
Next, lets try to pickup URLS for these posts, I made next query (using firepath of course): .//*[@id=’top-stories’]/div/h2/a[1]
And last query – for titles: .//*[@id=’top-stories’]/div/h2/a[1]/span
Step 1. PHP
So, what we have as result PHP file:
index.php
<?php
$sUrl = 'http://news.google.com/news/section?pz=1&cf=all&topic=t&ict=ln';
$sUrlSrc = getWebsiteContent($sUrl);
// Load the source
$dom = new DOMDocument();
@$dom->loadHTML($sUrlSrc);
$xpath = new DomXPath($dom);
// step 1 - links:
$aLinks = array();
$vRes = $xpath->query(".//*[@id='top-stories']/div/h2/a[1]");
foreach ($vRes as $obj) {
$aLinks[] = $obj->getAttribute('href');
}
// step 2 - titles:
$aTitles = array();
$vRes = $xpath->query(".//*[@id='top-stories']/div/h2/a[1]/span");
foreach ($vRes as $obj) {
$aTitles[] = $obj->nodeValue;
}
// step 3 - descriptions:
$aDescriptions = array();
$vRes = $xpath->query(".//*[@id='top-stories']/div/div[@class='body']/div[1]");
foreach ($vRes as $obj) {
$aDescriptions[] = $obj->nodeValue;
}
echo '<link href="css/styles.css" type="text/css" rel="stylesheet"/><div class="main">';
echo '<h1>Using xpath for dom html</h1>';
$entries = $xpath->evaluate('.//*[@id="headline-wrapper"]/div[1]/div/h2/span');
echo '<h1>' . $entries->item(0)->nodeValue . ' google news</h1>';
$i = 0;
foreach ($aLinks as $sLink) {
echo <<<EOF
<div class="unit">
<a href="{$sLink}">{$aTitles[$i]}</a>
<div>{$aDescriptions[$i]}</div>
</div>
EOF;
$i++;
}
echo '</div>';
// this function will return page content using caches (we will load original sources not more than once per hour)
function getWebsiteContent($sUrl) {
// our folder with cache files
$sCacheFolder = 'cache/';
// cache filename
$sFilename = date('YmdH').'.html';
if (! file_exists($sCacheFolder.$sFilename)) {
$ch = curl_init($sUrl);
$fp = fopen($sCacheFolder.$sFilename, 'w');
curl_setopt($ch, CURLOPT_FILE, $fp);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_HTTPHEADER, Array('User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.15) Gecko/20080623 Firefox/2.0.0.15'));
curl_exec($ch);
curl_close($ch);
fclose($fp);
}
return file_get_contents($sCacheFolder.$sFilename);
}
?>
Make attention that I always caching results (in ‘cache’ folder). This will help you to prevent often loading of source page (always when we calling our script). Script will take fresh file (page content) hourly. Ok, in PHP we can see that I collecting titles, urls and descriptions of our posts from google news page. And, in result – we will draw these collections to our screen.
XPath details (syntax, functions and arrays)
Lets review syntax of XPath query, as example we have: .//*[@id=’top-stories’]/div[2]/div[3]/div[1]
Here are .//* mean All(*) elements one or more levels deep in the current context. Instead * we can point any another element, DIV as example (.//div). All elements separated with / is path between elements. All inside [] is predicate. It can be digit (in this case this will index of element .//div[5] – will mean 5th DIV), or another checking logic. This is more interesting. Samples:
- .//div[@id=’top-stories’] – filter elements by ID, or by another attribute using @ symbol
- .//div[contains(text(),’iPhone’)] – filter by DIV elements which have ‘iPhone’ word – searching
- .//div[@id=’top-stories’]/div[last()] – last() command will return us last element in collection
- .//*[@id=’top-stories’]/div[position() > 5][position() < 10] – position() command will return position of element. In current sample I taking elements from 5 till 10.
- .//div[@id=’top-stories’]/div[position() mod 2 = 0] – mod – modulo. Here are all even elements.
Plus of course we can use logic operations (>, <, <=, >=) too.
Another sample file demonstrate another possibilities too:
index-2.php
<?php
$sUrl = 'http://news.google.com/news/section?pz=1&cf=all&topic=t&ict=ln';
$sUrlSrc = getWebsiteContent($sUrl);
// Load the source
$dom = new DOMDocument();
@$dom->loadHTML($sUrlSrc);
$xpath = new DomXPath($dom);
// all links contain 'iPhone':
$aLinks = array();
$vRes = $xpath->query(".//*[@id='top-stories']/div/h2/a[1]/span[contains(text(),'iPhone')]");
foreach ($vRes as $obj) {
$aLinks[$obj->nodeValue] = $obj->parentNode->getAttribute('href');
}
// all links from 5 to 10
$aLinks2 = array();
$vRes = $xpath->query(".//*[@id='top-stories']/div[position() > 5][position() < 10]/h2/a[1]/span");
foreach ($vRes as $obj) {
$aLinks2[$obj->nodeValue] = $obj->parentNode->getAttribute('href');
}
echo '<link href="css/styles.css" type="text/css" rel="stylesheet"/><div class="main">';
echo '<h1>Using xpath for dom html (2)</h1>';
echo '<h1>All links contain "iPhone" word</h1>';
foreach ($aLinks as $sTitle => $sLink) {
echo <<<EOF
<div class="unit">
<a href="{$sLink}">{$sTitle}</a>
</div>
EOF;
}
echo '<hr /><h1>Links from 5 to 10</h1>';
foreach ($aLinks2 as $sTitle => $sLink) {
echo <<<EOF
<div class="unit">
<a href="{$sLink}">{$sTitle}</a>
</div>
EOF;
}
echo '</div>';
// this function will return page content using caches (we will load original sources not more than once per hour)
function getWebsiteContent($sUrl) {
// our folder with cache files
$sCacheFolder = 'cache/';
// cache filename
$sFilename = date('YmdH').'.html';
if (! file_exists($sCacheFolder.$sFilename)) {
$ch = curl_init($sUrl);
$fp = fopen($sCacheFolder.$sFilename, 'w');
curl_setopt($ch, CURLOPT_FILE, $fp);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_HTTPHEADER, Array('User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.15) Gecko/20080623 Firefox/2.0.0.15'));
curl_exec($ch);
curl_close($ch);
fclose($fp);
}
return file_get_contents($sCacheFolder.$sFilename);
}
?>
In first case I will collect all links which contain ‘iPhone’ word, second – collection all links from 5 to 10.
Step 2. CSS
Here are used CSS file:
css/styles.css
body{background:#eee;font-family:Verdana, Helvetica, Arial, sans-serif;margin:0;padding:0}
.main{background:#FFF;width:800px;font-size:80%;border:1px #000 solid;margin:3.5em auto 2em;padding:1em 2em 2em}
h1{text-align:center}
.unit {margin:5px;padding:5px;border:1px solid #DDD;}
Here are just several styles for our demo.
Conclusion
Using easy sample I demonstrated possibilities of XPath. Possible someone still parsing web pages with regular expressions, but I hope that made good step for using XPath in your projects. As minimum – it will make your code more clean and easy. Good luck!